
鱼羊 henry 发自 麦蒿寺
量子位 | 公众号 QbitAI
2025倒计时,新SOTA模子裸露莫得放缓迹象。
今夜之间,编程SOTA模子易主,况且上线即开源,依然来自中国大模子公司——
智谱AI,GLM-4.7。
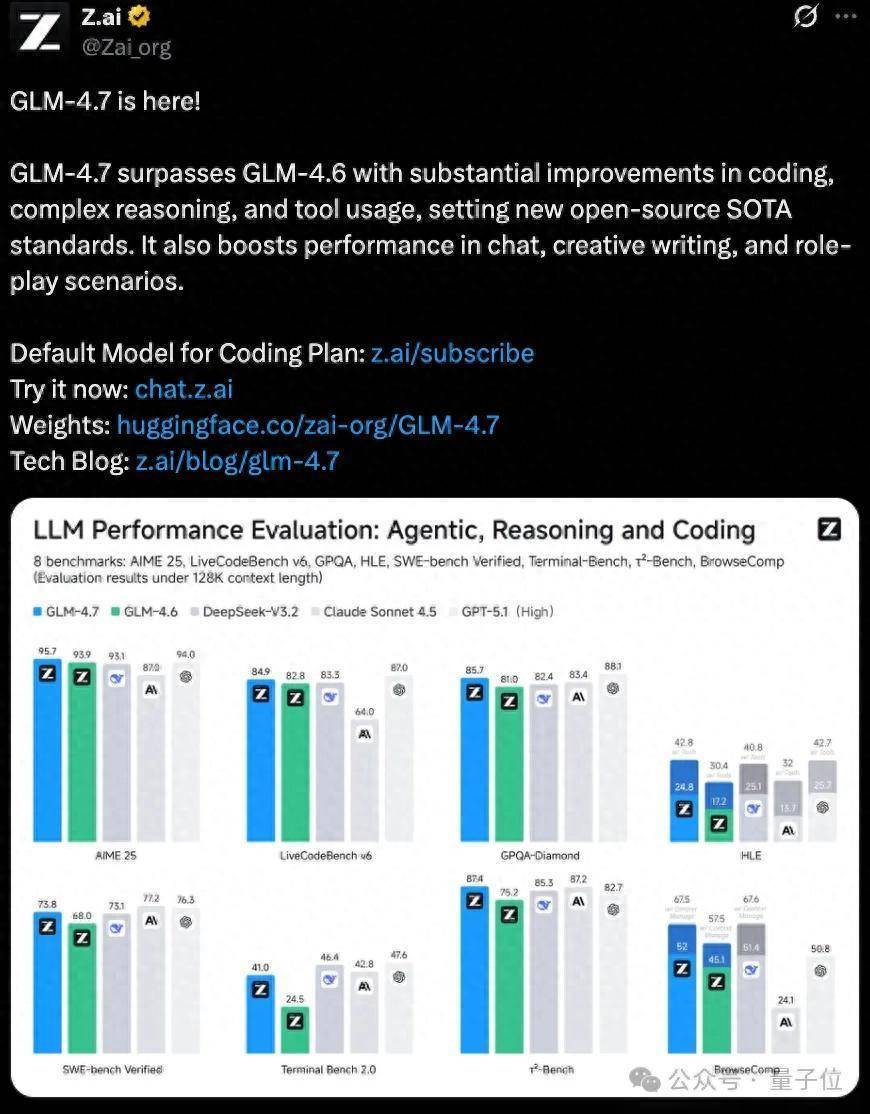
这波更新,时刻禀报里满眼皆是Coding,Coding,如故Coding。
而才能的进步,带来的最直不雅后果是:
AIME 25和东说念主类临了熟悉(HLE)等基准中,GLM-4.7分数超GPT-5.1;
SWE-Bench分数达(73.8%,+5.8%),创开源新高。
官方Demo骄横,写个植物大战僵尸不良友:
一言以蔽之,模子这样一发,双旦的节庆氛围一下到位了(doge)。
官网Chatbot和API均已就位,目下就能在线开玩。
Demo来吧,展示在前端生成质地上,GLM-4.7展现出彰着升级:页面结构更干净、组件层级更显明。
比较GLM-4.6,更像是当代的Web UI,网友元素中愈加好意思不雅。
在PPT与视觉物料生成方面,GLM-4.7标题层级明确、元素尺寸更合理。
在复杂几何结构与空间联系的抒发上,GLM-4.7模子或者保合手较好的结构一致性与细节褂讪性。
3D财富的生成质地也有显贵进步。
刷新开源SOTA
此次最新的模子主打编程,相较前代GLM-4.6,GLM-4.7在编码才能、交互体验与复杂推理等多个维度达成了系统性升级。
复杂推理才能(Reasoning):全面进步,HLE(含器具)42.8(+12.4 vs GLM-4.6),MMUL-Pro 84.3,GPQA-Diamond 85.7,数学与推理才能更稳更强。中枢编码才能(Code Agent):多谈话与末端任务显贵增强,SWE-bench Verified 73.8(+5.8)、SWE-bench Multilingual 66.7(+12.9)、Terminal Bench 2.0 41.0(+16.5),支撑“先想考、再行径”阵势。器具使用才能(General Agent):器具调用更高效,BrowseComp 52.0(+6.9)、BrowseComp w/ Context Management 67.5(+10.0)、τ²-Bench 87.4(+12.2),网页浏览与器具链处分推崇更优。
此外,GLM-4.7在对话、创意写稿、变装演出等场景中相通有进步,系统性增强了编码、推理与器具使用才能。
交错式想考和保留式想考
时刻方面,GLM-4.7强化了自GLM-4.5起引入的交错式想考(Interleaved Thinking),并进一步引入了保留式想考(Preserved thinking)和轮级想考(Turn-level Thinking)。
交错式想考
GLM在器具调用之间、收到器具赶走之后连续想考。
这让模子或者进行更复杂的永诀推理,进步了辅导驯顺和生成质地:
在决定下一步行径前先解读每次的器具输出,把屡次器具调用和推理步调串联起来,并凭据中间赶走作念出更细粒度的有辩论。
保留式想考
在编码场景中,GLM-4.7引入了一种新的想考阵势:
模子会自动在多回合对话中保留整个想考快,复用已有推理而不是重新再行推理。这减少了信息丢成仇不一致性,使得模子更适用于长程、复杂任务。还能在真实任务中从简更多tokens。
轮级想考
轮级想考是一种按轮司法推理筹画的才能,即在团结个会话中,每一轮央求皆不错零丁礼聘开启/关闭想考。
这使得GLM-4.7具备以下上风:
更纯果然本钱/时延司法:对“问个事实/改个措辞”等轻量轮次可关闭想考,追求快速反应;对“复杂盘算/多敛迹推理/代码调试”等重负务轮次可开启想考,进步正确率与褂讪性。更顺滑的多轮体验:想考开关在会话内可随时切换,模子能在不同轮次间保合手对话连贯与输出立场一致,让用户嗅觉“聪敏时更聪敏、简便时更快”。更相宜Agent/器具调用场景:在需要快速实施的器具轮次可镌汰推理支拨,在需要详尽器具赶走作念有辩论的轮次再开启深度想考,达收效力与质地的动态均衡。更多时刻治服,智谱官方也附上了良好时刻禀报。
BTW,智谱这个月还真上了“节日截止优惠”。
每月最低20元即可畅享GLM-4.7,用上Claude Pro套餐3倍用量。
又是一位好价钱屠户呀。
况且GLM-4.7的深夜炸场,也算是也曾冲刺IPO上市的智谱,带来的最新时刻诠释注解。
目下智谱也曾通过了港交所上市聆讯,IPO敲钟仅剩下临了100米。
而GLM-4.7可能亦然智谱上市之前,最病笃的模子更新了……吧?
参考聚会:
[1]https://z.ai/blog/glm-4.7
[2]https://x.com/Zai_org/status/2003156119087382683
— 完 —
量子位 QbitAI · 头条号
真贵咱们,第一时刻获知前沿科技动态